Load Records
The load records to a single object functionality allows loading a file to change to data in your Salesforce org.
Choose object and load file
After choosing which object you want to make changes to, you will need to provide a file to upload.
Jetstream supports the following file formats:
- CSV (.csv)
- Excel (.xslx)
- Google Sheet
- Choose the "Google Drive" tab to connect your Google account
Once you choose your file, you will be shown a preview of the data in a table, confirm that the data looks good.
Next, you need to choose the operation:
- Insert
- Update
- Upsert
- Create or update records, this requires selecting an External Id which is used to determine if the record should be created or updated
- Delete
Once you have everything configured, continue to Map Fields.
Map fields
The easiest way to prepare a file to load is to use the Query tool with the fields you want to load and download the records. This will give you an easy starting point to work from.
You will need to choose which fields from your CSV should be loaded into Salesforce and you need to map fields from your file to fields in Salesforce.
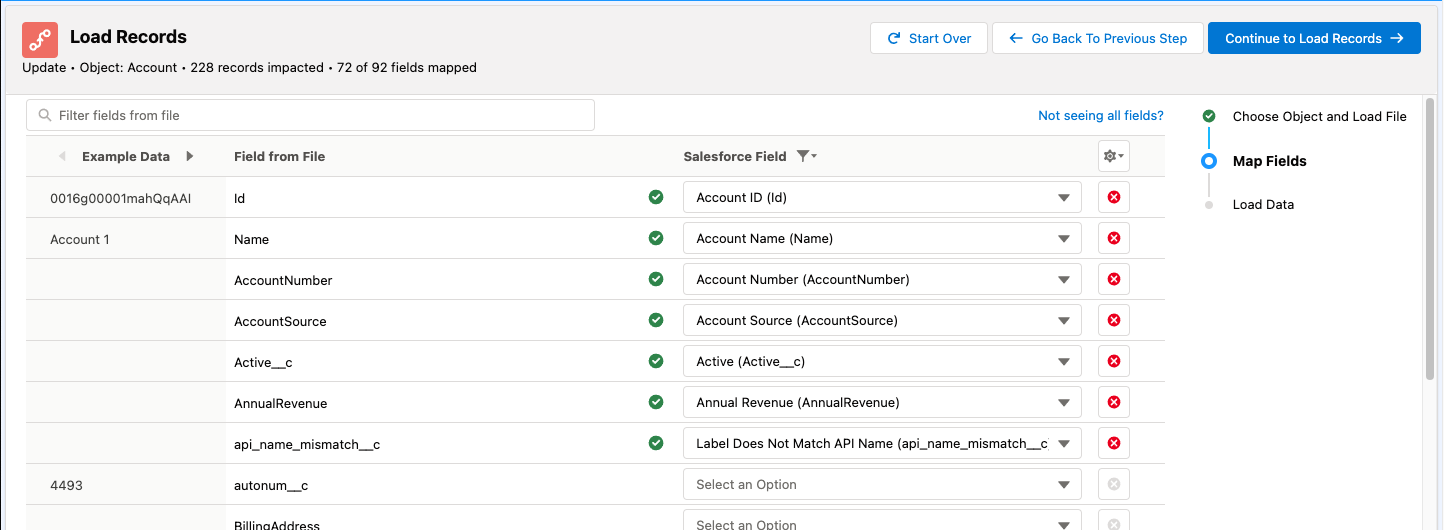
Auto-mapping
Jetstream will attempt to auto-map your file using the following strategy for each field in your file:
- Check for exact API name match
- Check for exact field label match
- Check for a match, ignoring any non-word characters
- If your file has a field with a period
., then Jetstream will attempt to match to a related field if possible- Example
Account.Name
- Example
Mapping to related fields
Instead of using an id to set a lookup field, you can map to a value on the related record to have Salesforce set the relationship for you.
- For inserts, you cannot map to the Record Id.
- For updates, you are required to map to the Record Id.
- For upsert, you are required to map to the chosen External Id.
- For delete, you can only map to the Record Id.
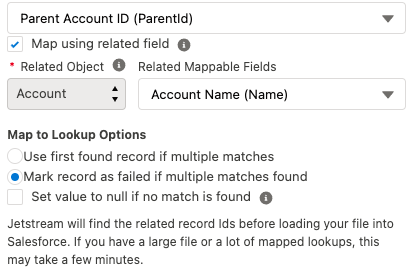
When you choose a lookup field, you will be presented with a few additional options:
- Related Object
- This will normally be disabled, but if the lookup field can look up to multiple objects (e.x. User or Queue) then you will need to choose which related object to load to. Salesforce calls this a "polymorphic relationship".
- Related Mappable Fields
- This is a list of all the mappable fields on the related object - This shows all text fields.
- Map to Lookup Options
- If you choose an External Id field, then this section will be disabled because Salesforce will set the lookup field based on an exact match for the external id.
- For all other fields, Jetstream will find the related records before loading the data into Salesforce.
- You will need to choose how to handle cases where no related record is found or multiple related records are found with the same matching value.
-
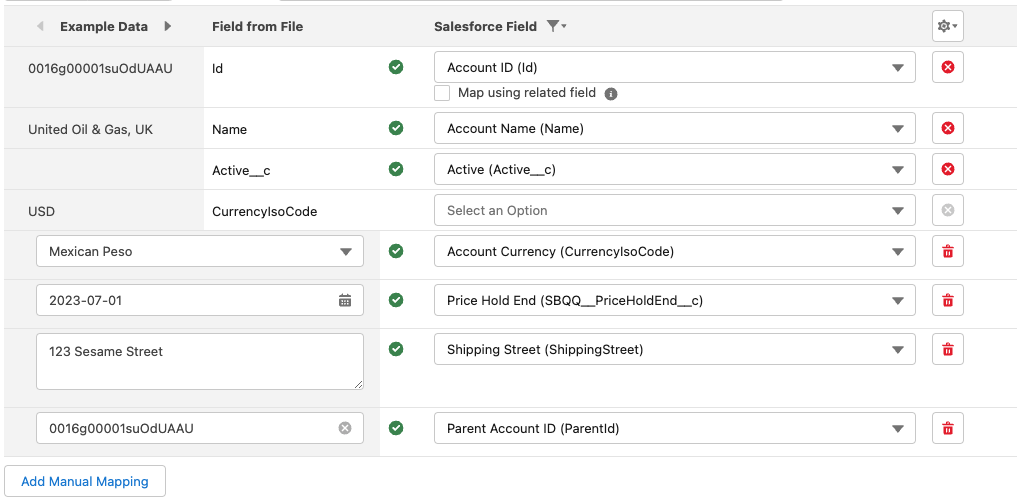
Add a value not included in your file
You can add a manual mapping for fields that are not in your file by clicking on the Add Manual Mapping button.
This will add a row to the mapping table and you will need to select a field and you can provide a value.
Load data
There are some final options available before loading your data to Salesforce.
API mode
- Bulk API - Best for very large data loads
- This will use the Salesforce Bulk API 1.0 to load your data.
- This will take longer and is optimized for high volume.
- Some types of automation may not be triggered when using the Bulk API.
- Batch API - Best for small to medium size loads
- This uses the sObject Collection API and is generally much faster than the Bulk API.
Some third party integrations, such as Zendesk for Salesforce, will not be notified of record changes when using the Bulk API.
Clear Fields with Blank Values
By default, if you have blank values (also called null values) in your input file, they will not modify the value for that field in Salesforce.
Choose this option if you would like blank values in your file to clear the value in Salesforce.
Serial Mode
This determines if records will be processed in parallel or not. This option is only available to be modified with the Bulk API.
Batch Size
The batch size determines how many records will be loaded at once.
You don't normally need to adjust this, but if you run into limits (e.x. CPU timeout or too many SOQL queries), then you can reduce this number to limit how many records are processed together.
- The free plan has an API limit of 1,000 calls per data load.
- If you are on a paid plan, you have an API limit of 5,000 calls per data load.
- If you are using the Browser Extension or Desktop App, there is no limit imposed by Jetstream.
Date Format
This will normally be auto-detected based on your locale, but make sure that it matches the format of the dates in your file.
Load results
Once your data load starts, you will see the results as they are being processed.
If you chose the Bulk API, you will be provided with a link to go view the bulk job in Salesforce.
After your load is finished, you will have the option to download all the results, or if there were one or more failed records, then you can download just the failed records.
When you download the results, the file will show all the data used to load into Salesforce and will only include columns for the mapped fields.

If you need to re-process the failed records, download the failure file and use that as your load file.